
As a powerful Enterprise Resource Planning (ERP) software that helps global enterprises organize, automate, and optimize their processes, Microsoft Dynamics AX has been the prime choice of mid-to-large size enterprises looking to seamlessly handle their finance and operations since the early 2000s.
However, this popular ERP is slowly becoming obsolete — primarily due to its on-premise nature. Companies looking to scale and digitally transform their businesses are now upgrading to Dynamics AX’s web-and-cloud-based counterpart, Microsoft Dynamics 365 Finance and Supply Chain Management.
Over the course of the last 18 years, we at To-Increase have helped many customers across industries upgrade their ERPs by performing data migrations — such as from AX 2009 to AX 2012, and from AX 2012 to Dynamics 365 Finance & Supply Chain Management. We have, therefore, not only perfected the guidelines and best practices you need to follow to achieve a successful data migration but also enhanced our no-code data migration and data quality software for D365 F&SCM.
Since migrating data from Dynamics AX to Dynamics 365 comes with its own set of data migration challenges, relying on the right software can make all the difference. Moreover, since a seamless turnkey migration from AX 2012 to D365 F&SCM isn’t fully supported by Microsoft, you can use our solution’s ODBC connection capabilities to ensure a successful data migration.
In this blog, we list out the 5 best practices for accomplishing a successful data migration from Dynamics AX to Dynamics 365 using ODBC.
But first, let’s take a look at what is ODBC and how it affects the data migration process.
What is ODBC?
Open Database Connectivity (ODBC) is an open standard Application Programming Interface (API) for accessing a database, introduced by Microsoft in 1992. Microsoft designed ODBC to be the answer to all database access problems ever imagined. It helps you access files in a number of different common databases.
In the context of data migration, migrating data from AX to D365 would involve loading data from one system to another, which can be complex and time-consuming. However, our data migration software allows you to load data using a direct ODBC connection, simplifying the data migration process. By effortlessly extracting data from Microsoft Dynamics AX versions 4.0, 2009, 2012, or any other application, and seamlessly integrating it with Microsoft Dynamics 365 Finance & Supply Chain Management, we enable you to bridge the gap between on-premise databases and the cloud.
Let’s look at the 5 ways in which ODBC facilitates a smoother migration from AX to D365.
5 best practices for migrating data from Dynamics AX to Dynamics 365 using ODBC
1. Use the ‘Process Type’ option to optimize the result
With an ODBC connection, you can read data from multiple tables while loading data from SQL. If you are dealing with fewer than 10,000 records, you can simplify the mapping by setting the process type option to ‘Query’ instead of ‘Direct’.
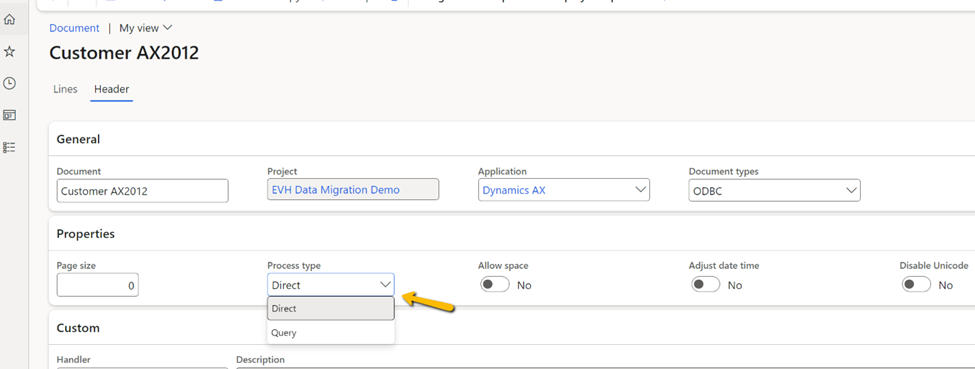
This way, the result would first get stored in the staging table. After that, an internal query would be used to read the data. You can manipulate the result of that query using the ‘Fetch Mode’ and ‘Join Mode’ options.
But if you have more than 10,000 records, it is better to process the ‘Direct’ option. It uses one transaction to store incoming data. The transaction ID is used to define the read set — therefore, we cannot commit multiple times. With the ‘Direct’ option, our data migration software will read record by record, making it harder to combine fields in the mapping.
2. Keep the query as simple as possible
When you are processing the query directly, you cannot easily combine multiple tables. Hence, you would need to use the query with one sub-table.
- Header
- Line
You can use the line table as an ‘exists join’ to limit the number of records. For example, when you need only the products in the current company, you can query them like this:
- Product
- Item
On the other hand, ‘joins’ to read other tables on the same level may not work in the mapping. Instead, you can query the addresses together with the zip code, city, and country/region. This can simplify the record ID conversion in the target system.
- Address
- Zip code
- City
- Country region
3. Use external ID conversion
External ID conversion can help limit the number of tables in the query. For example, in the case of an address, we can have a separate import for the zip code, city, and country or region. During this import, we can generate the external ID conversions which store the old record ID as well as the new record ID.
During the import of the address, you can also apply the external ID mapping per field. This helps you avoid the lookup of the table and simplifies the mapping, since now you don't need to find the correct zip code, city, or country/region.
4. Apply paging for multiple reads from the database
Data is imported using ODBC via the Azure Service Bus in Dynamics 365 for Finance & Supply Chain Management. The Azure Service Bus sends the result set back and converts it to text internally. However, there is a limit for this — so a read action cannot return more than 100,000 records in one go.
In order to solve this, you can use the paging quantity in the ODBC document. Keep in mind that the paging size should not exceed 100,000,000 records.
The paging will result in multiple threads which will be executed and processed in parallel. This means that you would be able to calculate what is most efficient per table (see the example below). When you need to load a lot of data where you process 40 records per second on average, you would be able to calculate the number of records as shown below.
When you use 8 threads for one batch server, you will see a result like this:
| Total number of records | 100,000,000 |
| Average speed for records per second | 40 |
| Number of threads | 8 |
| Records per second | 320 |
| Max. throughput time in hours | 87 |
You should add more capacity to your batch server (more CPUs), or more batch servers. You need at least one CPU per thread—and, of course, some threads for other tasks. When you have 40 threads available (5 batch servers) you will be able to accomplish a full migration in 17 hours. (See the example below)
| Total number of records | 100,000,000 |
| Average speed for records per second | 40 |
| Number of threads | 40 |
| Records per second | 1,600 |
| Max. throughput time in hours | 17 |
5. Parallel processing using tasks
With ODBC, you can use the task setup to use parallel processing. The task setup can help you run the migration in the correct sequence. For each task, you can define the list of messages which should have the same dependency. Since each task can have a dependency on one or more other tasks, it would have to wait until the other tasks are finished.
When the tasks have been set up, you can run the project. The project will run the tasks with the same dependency at the same time, if possible. Since the messages can use the paging functionality, each task will run the linked messages simultaneously.
TIP: When you need to define the dependencies per message, you can use the XRefTableRelation table.
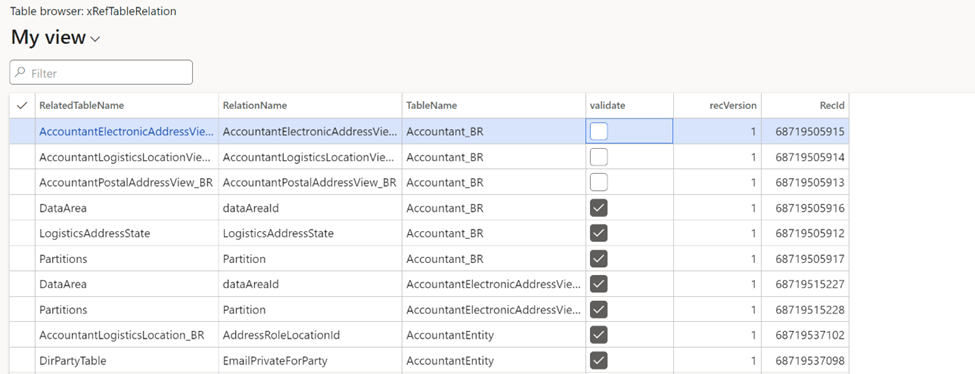
During any data import, we tend to validate all incoming data, thus slowing down the system. But when you apply the ODBC settings correctly, you can take advantage of a scalable and predictable way to migrate data.
To sum it up, embracing ODBC not only minimizes risk but also simplifies project execution, making it a widely recognized best practice among businesses and their technology partners.
Easily navigate your data migration journey with our Data Migration solution for D365 F&SCM
By using ODBC in connection with To-Increase’s Data Migration solution, you can easily upgrade from Dynamics AX to Dynamics 365 F&SCM with speed, accuracy, and efficiency. To-Increase’s no-code Data Migration solution not only helps you with data exports and imports to Dynamics 365 but is also capable of validating and de-duplicating your legacy system data during the data migration process.
Most importantly, our Data Migration solution can help you ensure that your data migration to D365 can be executed with just one click!
Ready to elevate your data migration experience? Download our Data Migration solution factsheet linked below to understand the solution benefits and features in depth.
.png)







